one-off-projects
Wordle Stats
Data from the NYT
The word list comes from
this JS
file. Look for var Ma= to see the list. You can see the full code
here
library(tidyverse)
library(glue)
library(gt)
library(scales)
library(simplecolors)
# read in NYT data
raw_words <-
read_csv("input/nyt_word_list.csv") |>
as_tibble() |>
print()
# A tibble: 2,309 x 1
word
<chr>
1 cigar
2 rebut
3 sissy
4 humph
5 awake
# ... with 2,304 more rows
# Break out each letter into its own column
word_letters <-
raw_words |>
separate(
col = word,
sep = "",
into = paste0("x", 0:5),
remove = FALSE
) |>
select(-x0) |>
print()
# A tibble: 2,309 x 6
word x1 x2 x3 x4 x5
<chr> <chr> <chr> <chr> <chr> <chr>
1 cigar c i g a r
2 rebut r e b u t
3 sissy s i s s y
4 humph h u m p h
5 awake a w a k e
# ... with 2,304 more rows
# Pivot the data to long-form and tally up frequencies
word_letters_long <-
word_letters |>
pivot_longer(
cols = starts_with("x"),
names_to = "position",
values_to = "letter"
) |>
# times letter was used at all
add_count(letter, name = "letter_freq") |>
# times letter was used in position
add_count(letter, position, name = "position_freq") |>
print()
# A tibble: 11,545 x 5
word position letter letter_freq position_freq
<chr> <chr> <chr> <int> <int>
1 cigar x1 c 475 198
2 cigar x2 i 670 201
3 cigar x3 g 310 67
4 cigar x4 a 975 162
5 cigar x5 r 897 212
# ... with 11,540 more rows
# Pivot wider
word_letter_freq <-
word_letters_long |>
select(word, pos = letter, position, freq = position_freq) |>
pivot_wider(
names_from = position,
values_from = c(pos, freq)
) |>
rename_all(str_remove_all, "pos_") |>
print()
# A tibble: 2,309 x 11
word x1 x2 x3 x4 x5 freq_x1 freq_x2 freq_x3 freq_x4 freq_x5
<chr> <chr> <chr> <chr> <chr> <chr> <int> <int> <int> <int> <int>
1 cigar c i g a r 198 201 67 162 212
2 rebut r e b u t 105 241 56 82 253
3 sissy s i s s y 365 201 80 171 364
4 humph h u m p h 69 185 61 50 137
5 awake a w a k e 140 44 306 55 422
# ... with 2,304 more rows
# Letters by total count and frequency in positions 1:5
letter_stats <-
word_letters_long |>
distinct(letter, letter_freq, position, position_freq) |>
pivot_wider(
names_from = position,
values_from = position_freq,
values_fill = 0
) |>
arrange(desc(letter_freq))
| letter | # words | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| e | 1230 | 72 | 241 | 177 | 318 | 422 |
| a | 975 | 140 | 304 | 306 | 162 | 63 |
| r | 897 | 105 | 267 | 163 | 150 | 212 |
| o | 753 | 41 | 279 | 243 | 132 | 58 |
| t | 729 | 149 | 77 | 111 | 139 | 253 |
| l | 716 | 87 | 200 | 112 | 162 | 155 |
| i | 670 | 34 | 201 | 266 | 158 | 11 |
| s | 668 | 365 | 16 | 80 | 171 | 36 |
| n | 573 | 37 | 87 | 137 | 182 | 130 |
| c | 475 | 198 | 40 | 56 | 150 | 31 |
| u | 466 | 33 | 185 | 165 | 82 | 1 |
| y | 424 | 6 | 22 | 29 | 3 | 364 |
| d | 393 | 111 | 20 | 75 | 69 | 118 |
| h | 387 | 69 | 144 | 9 | 28 | 137 |
| p | 365 | 141 | 61 | 57 | 50 | 56 |
| m | 316 | 107 | 38 | 61 | 68 | 42 |
| g | 310 | 115 | 11 | 67 | 76 | 41 |
| b | 280 | 173 | 16 | 56 | 24 | 11 |
| f | 229 | 135 | 8 | 25 | 35 | 26 |
| k | 210 | 20 | 10 | 12 | 55 | 113 |
| w | 194 | 82 | 44 | 26 | 25 | 17 |
| v | 152 | 43 | 15 | 49 | 45 | 0 |
| z | 40 | 3 | 2 | 11 | 20 | 4 |
| x | 37 | 0 | 14 | 12 | 3 | 8 |
| q | 29 | 23 | 5 | 1 | 0 | 0 |
| j | 27 | 20 | 2 | 3 | 2 | 0 |
# Create metrics for each word. letter_stats$letter is a factor so `letters
word_stats <-
word_letters_long |>
mutate(
letter = factor(letter, levels = letter_stats$letter, ordered = TRUE),
letter_ord = as.integer(letter)
) |>
group_by(word) |>
arrange(letter) |>
summarise(
alpha = paste(sort(as.character(letter)), collapse = ""),
n_letter = n_distinct(letter),
n_1_5 = sum(letter %in% letter_stats$letter[1:5]),
n_6_10 = sum(letter %in% letter_stats$letter[6:10]),
n_10_15 = sum(letter %in% letter_stats$letter[10:15]),
n_12_26 = sum(letter %in% letter_stats$letter[12:26]),
# are the letters closest to the top (1:26, lower is better)
mean_letter_rank = mean(letter_ord),
# are the letter closer to their most common positions (higher is better)
mean_pos_freq = mean(position_freq)
#,mean_letter_freq = mean(letter_freq),sum_letter_freq = sum(letter_freq)
) |>
ungroup() |>
arrange(mean_letter_rank) |>
print()
# A tibble: 2,309 x 9
word alpha n_letter n_1_5 n_6_10 n_10_15 n_12_26 mean_letter_rank
<chr> <chr> <int> <int> <int> <int> <int> <dbl>
1 eater aeert 4 5 0 0 0 2.4
2 rarer aerrr 3 5 0 0 0 2.4
3 eerie eeeir 3 4 1 0 0 2.6
4 error eorrr 3 5 0 0 0 2.8
5 terra aerrt 4 5 0 0 0 2.8
# ... with 2,304 more rows, and 1 more variable: mean_pos_freq <dbl>
# find words that have 5 distinct values
distinct_letters <-
word_stats |>
filter(n_letter == 5) |>
print()
# A tibble: 1,562 x 9
word alpha n_letter n_1_5 n_6_10 n_10_15 n_12_26 mean_letter_rank
<chr> <chr> <int> <int> <int> <int> <int> <dbl>
1 alert aelrt 5 4 1 0 0 3.4
2 alter aelrt 5 4 1 0 0 3.4
3 later aelrt 5 4 1 0 0 3.4
4 arose aeors 5 4 1 0 0 3.6
5 irate aeirt 5 4 1 0 0 3.6
# ... with 1,557 more rows, and 1 more variable: mean_pos_freq <dbl>
# roll-up words by patterns (for regex)
as_patterns <-
distinct_letters |>
# roll up words by best placement
group_by(alpha) |>
arrange(desc(mean_pos_freq)) |>
summarise(
words = paste(word, collapse = ","),
mean_letter_rank = mean(mean_letter_rank), # same across all values
across(matches("n_\\d"), mean),
) |>
ungroup() |>
# create pattern column, move to front
# mutate(
# pattern = str_replace_all(alpha, "(.)(?=.)", "\\1|"),
# .before = everything()
# ) |>
arrange(mean_letter_rank) |>
print()
# A tibble: 1,391 x 7
alpha words mean_letter_rank n_1_5 n_6_10 n_10_15 n_12_26
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 aelrt later,alter,alert 3.4 4 1 0 0
2 aeirt irate 3.6 4 1 0 0
3 aeors arose 3.6 4 1 0 0
4 aerst stare 3.8 4 1 0 0
5 acert crate,trace,cater,react 4.2 4 1 1 0
# ... with 1,386 more rows
# best starting words primarily from letters 1-5: later, irate, stare, arose, stare, crate
as_patterns |>
filter(n_1_5 >= 4) |>
head(3)
# A tibble: 3 x 7
alpha words mean_letter_rank n_1_5 n_6_10 n_10_15 n_12_26
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 aelrt later,alter,alert 3.4 4 1 0 0
2 aeirt irate 3.6 4 1 0 0
3 aeors arose 3.6 4 1 0 0
# best 2nd word from 6-10: slain, slice, since, sonic, sling, cling, slink, slick
as_patterns |>
filter(n_6_10 >= 4) |>
head(3)
# A tibble: 3 x 7
alpha words mean_letter_rank n_1_5 n_6_10 n_10_15 n_12_26
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 ailns slain,snail 6.4 1 4 0 0
2 ceils slice 6.4 1 4 1 0
3 ceins since 7 1 4 1 0
# best 3rd words from letters 10-15: duchy, dutch, pouch, punch, pushy, chump, dumpy, pudgy
as_patterns |>
filter(n_10_15 >= 4) |>
arrange(desc(n_10_15), mean_letter_rank) |>
head(3)
# A tibble: 3 x 7
alpha words mean_letter_rank n_1_5 n_6_10 n_10_15 n_12_26
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 cdhuy duchy 12 0 1 5 3
2 cdhtu dutch 10.6 1 1 4 2
3 chopu pouch 10.8 1 1 4 2
# best remaining words from rest of alphabet: gawky, maybe, foamy, gumbo, buxom, jumbo
as_patterns |>
filter(n_12_26 >= 3) |>
filter(!str_detect(alpha, "[rtlsncdhp]")) |>
arrange(desc(n_12_26)) |>
head(3)
# A tibble: 3 x 7
alpha words mean_letter_rank n_1_5 n_6_10 n_10_15 n_12_26
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 agkwy gawky 14.4 1 0 1 4
2 abemy maybe 9.8 2 0 1 3
3 afmoy foamy 10.6 2 0 1 3
# Look for next best word once existing letters have been used
find_next <- function(use_pattern, suffix = "") {
as_patterns |>
# see which are used the fewest
mutate(found = str_count(alpha, glue("[{use_pattern}]"))) |>
arrange(found, mean_letter_rank) |>
slice(1) |>
distinct(alpha, words, rank = mean_letter_rank) |>
rename_all(paste0, suffix)
}
# best starting word
find_next(use_pattern = ".")
# A tibble: 1 x 3
alpha words rank
<chr> <chr> <dbl>
1 aelrt later,alter,alert 3.4
# best word after [aelrt] (later, alter, alert)
find_next(use_pattern = "aelrt")
# A tibble: 1 x 3
alpha words rank
<chr> <chr> <dbl>
1 cinos sonic,scion 7.6
# best word after [aelrt] + [cinos] (sonic, scion)
find_next(use_pattern = "aelrtcinos")
# A tibble: 1 x 3
alpha words rank
<chr> <chr> <dbl>
1 dmpuy dumpy 13.4
# Find best sequences
best_sequences <-
as_patterns |>
filter(n_1_5 >= 4) |>
distinct(
alpha_1 = alpha,
words_1 = words,
rank_1 = mean_letter_rank
) |>
mutate(
second = map(
.x = alpha_1,
.f = find_next,
suffix = "_2"
)
) |>
unnest_wider(second) |>
mutate(
third = map(
.x = paste0(alpha_1, alpha_2),
.f = find_next,
suffix = "_3"
)
) |>
unnest_wider(third) |>
mutate(
forth = map(
.x = paste0(alpha_1, alpha_2, alpha_3),
.f = find_next,
suffix = "_4"
)
) |>
unnest_wider(forth) |>
mutate(
n_distinct = map_chr(
.x = paste(alpha_1, alpha_2, alpha_3, alpha_4),
.f =
~ str_split(.x, "") |>
unlist() |>
unique() |>
length()
),
sum_rank = (rank_1 + rank_2 + rank_3)
) |>
arrange(desc(n_distinct), sum_rank)
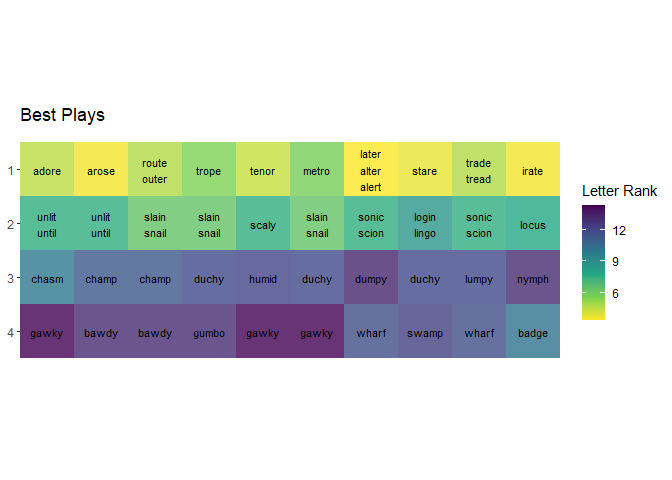
head(best_sequences, 5)
# A tibble: 5 x 14
alpha_1 words_1 rank_1 alpha_2 words_2 rank_2 alpha_3 words_3 rank_3 alpha_4
<chr> <chr> <dbl> <chr> <chr> <dbl> <chr> <chr> <dbl> <chr>
1 adeor adore 4.6 ilntu unlit,~ 7.6 achms chasm 10 agkwy
2 aeors arose 3.6 ilntu unlit,~ 7.6 achmp champ 11.4 abdwy
3 eortu route,ou~ 4.8 ailns slain,~ 6.4 achmp champ 11.4 abdwy
4 eoprt trope 5.6 ailns slain,~ 6.4 cdhuy duchy 12 bgmou
5 enort tenor 4.4 aclsy scaly 7.6 dhimu humid 12.2 agkwy
# ... with 4 more variables: words_4 <chr>, rank_4 <dbl>, n_distinct <chr>,
# sum_rank <dbl>
# Create plot
best_sequences |>
head(10) |>
select(starts_with(words), starts_with("rank")) |>
mutate(order = row_number()) |>
mutate_all(as.character) |>
pivot_longer(
-order,
names_to = c("type", "id"),
names_sep = "_"
) |>
pivot_wider(
names_from = type,
values_from = value
) |>
mutate(across(c(order, id, rank), as.numeric)) |> #print()
ggplot(aes(order, id)) +
geom_tile(aes(fill = rank), alpha = 0.8) +
geom_text(
aes(label = str_replace_all(words, ",", "\n")),
size = 3
) +
scale_fill_viridis_c(
option = "D",
direction = -1
) +
scale_x_continuous(expand = expansion()) +
scale_y_reverse() +
coord_fixed() +
theme(
panel.background = element_rect(fill = "white", color = "white"),
axis.title = element_blank(),
axis.text.x = element_blank(),
axis.ticks.x = element_blank()
) +
labs(
title = "Best Plays",
fill = "Letter Rank"
)
# best series: from nytimes js
# adore # arose # route # trope
# until # unlit # slain # slain
# chasm # champ # champ # duchy
# gawky # bawdy # bawdy # gumbo
# best series: from dictionary
# arose # arose
# unlit # clint
# champ # dumpy
# gawky # hawks
# solving wordle
# example: floor - has [lor] but not [ais...], [l] is the 2nd letter
str_detect_each <- function(x, letters) {
pattern <-
str_split(letters, "")[[1]] |>
sort() |>
paste(collapse = "|")
matches <-
str_extract_all(x, pattern) |>
map(pluck) |>
map(sort) |>
map_chr(paste, collapse = "|")
matches == pattern
}
word_stats |>
# green
filter(str_detect(word, "s.a..")) |> # these are filled in
# yellow
filter(str_detect_each(word, "te")) |> # has these other letters
filter(!str_detect(word, "...[t].")) |> # t is not in the 3rd position
# grey
filter(!str_detect(word, "[liopr]")) # none of these letters
# A tibble: 3 x 9
word alpha n_letter n_1_5 n_6_10 n_10_15 n_12_26 mean_letter_rank
<chr> <chr> <int> <int> <int> <int> <int> <dbl>
1 stage aegst 5 3 1 0 1 6.6
2 stake aekst 5 3 1 0 1 7.2
3 stave aestv 5 3 1 0 1 7.6
# ... with 1 more variable: mean_pos_freq <dbl>